Enmascaramiento de datos
¿Qué es el enmascaramiento de datos?
El enmascaramiento de datos es una forma de crear una versión falsa, pero realista, de los datos de su organización. El objetivo es proteger los datos confidenciales y, al mismo tiempo, ofrecer una alternativa funcional cuando no se necesitan datos reales; por ejemplo, en la formación de usuarios, las demostraciones de ventas o las pruebas de software.
Los procesos de enmascaramiento de datos cambian los valores de los datos mientras utilizan el mismo formato. El objetivo es crear una versión que no pueda ser descifrada o sometida a ingeniería inversa. Hay varias formas de alterar los datos, incluyendo el barajado de caracteres, la sustitución de palabras o caracteres y el cifrado.
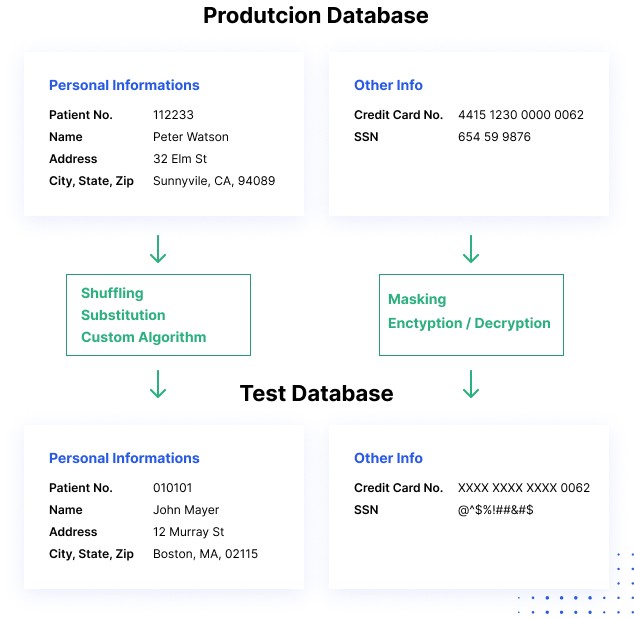
Cómo funciona el enmascaramiento de datos
¿Por qué es importante el enmascaramiento de datos?
Hay varias razones por las que el enmascaramiento de datos es esencial para muchas organizaciones:
- El enmascaramiento de datos resuelve varias amenazas críticas: la pérdida de datos, la exfiltración de datos, las amenazas internas o el compromiso de cuentas, y las interfaces inseguras con sistemas de terceros.
- Reduce los riesgos de datos asociados a la adopción de la nube.
- Hace que los datos sean inútiles para un atacante, a la vez que mantiene muchas de sus propiedades funcionales inherentes.
- Permite compartir datos con usuarios autorizados, como probadores y desarrolladores, sin exponer los datos de producción.
- Puede utilizarse para la higienización de datos: la eliminación normal de archivos sigue dejando rastros de datos en los medios de almacenamiento, mientras que la higienización sustituye los valores antiguos por otros enmascarados.
Tipos de enmascaramiento de datos
Hay varios tipos de enmascaramiento de datos comúnmente utilizados para asegurar los datos sensibles.
Enmascaramiento de datos estático
Los procesos de enmascaramiento de datos estáticos pueden ayudarle a crear una copia saneada de la base de datos. El proceso altera todos los datos sensibles hasta que una copia de la base de datos pueda ser compartida con seguridad. Normalmente, el proceso consiste en crear una copia de seguridad de una base de datos en producción, cargarla en un entorno separado, eliminar cualquier dato innecesario y, a continuación, enmascarar los datos mientras están en estasis. La copia enmascarada puede entonces ser empujada a la ubicación de destino.
Máscara de datos determinista
Involucra el mapeo de dos conjuntos de datos que tienen el mismo tipo de datos, de tal manera que un valor es siempre reemplazado por otro valor. Por ejemplo, el nombre «John Smith» se sustituye siempre por «Jim Jameson», siempre que aparezca en una base de datos. Este método es conveniente para muchos escenarios, pero es inherentemente menos seguro.
Enmascaramiento de datos sobre la marcha
Enmascarar los datos mientras se transfieren de los sistemas de producción a los sistemas de prueba o desarrollo antes de que los datos se guarden en el disco. Las organizaciones que despliegan software con frecuencia no pueden crear una copia de seguridad de la base de datos de origen y aplicar el enmascaramiento; necesitan una forma de transmitir continuamente los datos de producción a varios entornos de prueba.
Sobre la marcha, el enmascaramiento envía subconjuntos más pequeños de datos enmascarados cuando se necesitan. Cada subconjunto de datos enmascarados se almacena en el entorno de desarrollo/prueba para su uso por el sistema que no es de producción.
Es importante aplicar el enmascaramiento sobre la marcha a cualquier alimentación de un sistema de producción a un entorno de desarrollo, al principio de un proyecto de desarrollo, para evitar problemas de cumplimiento y seguridad.
Enmascaramiento dinámico de datos
Similar al enmascaramiento sobre la marcha, pero los datos nunca se almacenan en un depósito de datos secundario en el entorno de desarrollo/prueba. En su lugar, se transmiten directamente desde el sistema de producción y son consumidos por otro sistema en el entorno de desarrollo/prueba.
Técnicas de enmascaramiento de datos
Revisemos algunas formas comunes en que las organizaciones aplican el enmascaramiento a los datos sensibles. Al proteger los datos, los profesionales de TI pueden utilizar una variedad de técnicas.
Encriptación de datos
Cuando los datos se encriptan, se vuelven inútiles a menos que el espectador tenga la clave de descifrado. Esencialmente, los datos son enmascarados por el algoritmo de encriptación. Esta es la forma más segura de enmascaramiento de datos, pero también es compleja de implementar porque requiere una tecnología para realizar el cifrado de datos en curso, y mecanismos para gestionar y compartir las claves de cifrado
Data Scrambling
Los caracteres se reorganizan en orden aleatorio, reemplazando el contenido original. Por ejemplo, un número de identificación como 76498 en una base de datos de producción, podría ser reemplazado por 84967 en una base de datos de prueba. Este método es muy sencillo de implementar, pero sólo puede aplicarse a algunos tipos de datos, y es menos seguro.
Nulling Out
Los datos aparecen perdidos o «nulos» cuando los ve un usuario no autorizado. Esto hace que los datos sean menos útiles para fines de desarrollo y pruebas.
Varianza de valores
Los valores originales de los datos se sustituyen por una función, como la diferencia entre el valor más bajo y el más alto de una serie. Por ejemplo, si un cliente compró varios productos, el precio de compra puede ser reemplazado por un rango entre el precio más alto y el más bajo pagado. Esto puede proporcionar datos útiles para muchos fines, sin revelar el conjunto de datos original.
Sustitución de datos
Los valores de los datos se sustituyen por valores alternativos falsos, pero realistas. Por ejemplo, los nombres reales de los clientes se sustituyen por una selección aleatoria de nombres de una agenda telefónica.
Barajada de datos
Similar a la sustitución, excepto que los valores de los datos se cambian dentro del mismo conjunto de datos. Los datos se reorganizan en cada columna utilizando una secuencia aleatoria; por ejemplo, cambiando los nombres reales de los clientes en varios registros de clientes. El conjunto de salida se parece a los datos reales, pero no muestra la información real de cada individuo o registro de datos.
Pseudonimización
Según el Reglamento General de Protección de Datos (RGPD) de la UE, se ha introducido un nuevo término para cubrir procesos como el enmascaramiento de datos, el cifrado y el hashing para proteger los datos personales: la seudonimización.
La seudonimización, tal y como se define en el RGPD, es cualquier método que garantice que los datos no puedan utilizarse para la identificación personal. Requiere eliminar los identificadores directos y, preferiblemente, evitar múltiples identificadores que, combinados, puedan identificar a una persona.
Además, las claves de cifrado, u otros datos que puedan utilizarse para volver a los valores originales de los datos, deben almacenarse por separado y de forma segura.
Mejores prácticas de enmascaramiento de datos
Determinar el alcance del proyecto
Para llevar a cabo el enmascaramiento de datos de forma eficaz, las empresas deben saber qué información debe protegerse, quién está autorizado a verla, qué aplicaciones utilizan los datos y dónde residen, tanto en dominios de producción como de no producción. Aunque esto puede parecer fácil sobre el papel, debido a la complejidad de las operaciones y a las múltiples líneas de negocio, este proceso puede requerir un esfuerzo considerable y debe planificarse como una etapa separada del proyecto.
Asegurar la integridad referencial
La integridad referencial significa que cada «tipo» de información procedente de una aplicación empresarial debe enmascararse utilizando el mismo algoritmo.
En las grandes organizaciones, una única herramienta de enmascaramiento de datos utilizada en toda la empresa no es factible. Es posible que cada línea de negocio tenga que implementar su propio enmascaramiento de datos debido a los requisitos presupuestarios/negocios, a las diferentes prácticas de administración de TI o a los diferentes requisitos de seguridad/reglamentarios.
Asegúrese de que las diferentes herramientas y prácticas de enmascaramiento de datos en toda la organización estén sincronizadas, cuando se trate del mismo tipo de datos. Esto evitará problemas más adelante cuando los datos deban utilizarse en todas las líneas de negocio.
Asegurar los algoritmos de enmascaramiento de datos
Es fundamental considerar cómo proteger los algoritmos de elaboración de datos, así como los conjuntos de datos alternativos o los diccionarios utilizados para codificar los datos. Dado que sólo los usuarios autorizados deben tener acceso a los datos reales, estos algoritmos deben considerarse extremadamente sensibles. Si alguien se entera de qué algoritmos de enmascaramiento repetitivos se están utilizando, puede aplicar ingeniería inversa a grandes bloques de información sensible.
Una de las mejores prácticas de enmascaramiento de datos, que se exige explícitamente en algunas normativas, es garantizar la separación de funciones. Por ejemplo, el personal de seguridad informática determina qué métodos y algoritmos se utilizarán en general, pero los ajustes específicos de los algoritmos y las listas de datos deben ser accesibles sólo para los propietarios de los datos en el departamento correspondiente.
Enmascaramiento de datos con Imperva
Imperva es una solución de seguridad que proporciona capacidades de enmascaramiento y cifrado de datos, permitiéndole ofuscar datos sensibles para que sean inútiles para un atacante, incluso si se extraen de alguna manera.
Además de proporcionar enmascaramiento de datos, la solución de seguridad de datos de Imperva protege sus datos dondequiera que vivan: en las instalaciones, en la nube y en entornos híbridos. También proporciona a los equipos de seguridad y de TI una visibilidad completa de cómo se accede a los datos, cómo se utilizan y cómo se mueven por la organización.
Nuestro enfoque integral se basa en múltiples capas de protección, que incluyen:
- Firewall de base de datos: bloquea la inyección SQL y otras amenazas, al tiempo que evalúa las vulnerabilidades conocidas.
- Gestión de derechos de usuario: supervisa el acceso a los datos y las actividades de los usuarios con privilegios para identificar los privilegios excesivos, inapropiados y no utilizados.
- Prevención de pérdida de datos (DLP): inspecciona los datos en movimiento, en reposo en los servidores, en el almacenamiento en la nube o en los dispositivos de punto final.
- Análisis del comportamiento del usuario: establece líneas de base del comportamiento de acceso a los datos, utiliza el aprendizaje automático para detectar y alertar sobre actividades anormales y potencialmente arriesgadas.
- Descubrimiento y clasificación de datos: revela la ubicación, el volumen y el contexto de los datos en las instalaciones y en la nube.
- Supervisión de la actividad de las bases de datos: supervisa las bases de datos relacionales, los almacenes de datos, los big data y los mainframes para generar alertas en tiempo real sobre las infracciones de las directivas.
- Priorización de las alertas: Imperva utiliza la tecnología de IA y de aprendizaje automático para examinar el flujo de eventos de seguridad y priorizar los más importantes.
Leave a Reply