Búsqueda de cuadrículas para el ajuste del modelo
Un hiperparámetro del modelo es una característica de éste que es externa al modelo y cuyo valor no puede estimarse a partir de los datos. El valor del hiperparámetro debe fijarse antes de que comience el proceso de aprendizaje. Por ejemplo, c en las máquinas de vectores de apoyo, k en k-Nearest Neighbors, el número de capas ocultas en las redes neuronales.
En cambio, un parámetro es una característica interna del modelo y su valor puede estimarse a partir de los datos. Por ejemplo, los coeficientes beta de la regresión lineal/logística o los vectores de soporte en las máquinas de vectores de soporte.
La búsqueda en cuadrícula se utiliza para encontrar los hiperparámetros óptimos de un modelo que da lugar a las predicciones más «precisas».
Veamos la búsqueda en cuadrícula construyendo un modelo de clasificación en el conjunto de datos del cáncer de mama.
Importar el conjunto de datos y ver las 10 primeras filas.
Salida :

Cada fila del conjunto de datos tiene una de dos clases posibles: benigna (representada por 2) y maligna (representada por 4). Además, hay 10 atributos en este conjunto de datos (mostrados arriba) que se utilizarán para la predicción, excepto el número de código de muestra que es el número de identificación.
Limpie los datos y cambie el nombre de los valores de la clase como 0/1 para la construcción del modelo (donde 1 representa un caso maligno). Además, observemos la distribución de la clase.
Salida :

Hay 444 casos benignos y 239 malignos.
Salida :
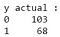
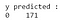
De la salida, podemos observar que hay 68 casos malignos y 103 benignos en el conjunto de datos de prueba. Sin embargo, nuestro clasificador predice todos los casos como benignos (ya que es la clase mayoritaria).
Calcule la métrica de evaluación de este modelo.
Salida :

La precisión del modelo es del 60.2%, pero este es un caso en el que la precisión puede no ser la mejor métrica para evaluar el modelo. Así que, echemos un vistazo a las otras métricas de evaluación.

La figura anterior es la matriz de confusión, con etiquetas y colores añadidos para una mejor intuición (El código para generar esto se puede encontrar aquí). Para resumir la matriz de confusión : VERDADEROS POSITIVOS (TP)= 0,VERDADEROS NEGATIVOS (TN)= 103,FALSOS POSITIVOS (FP)= 0, FALSOS NEGATIVOS (FN)= 68. Las fórmulas de las métricas de evaluación son las siguientes :

Como el modelo no clasifica correctamente ningún caso maligno, las métricas de recuerdo y precisión son 0.
Ahora que tenemos la precisión de referencia, vamos a construir un modelo de regresión logística con parámetros por defecto y evaluar el modelo.
Salida :

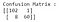
Al ajustar el modelo de Regresión Logística con los parámetros por defecto, tenemos un modelo mucho «mejor». La exactitud es del 94,7% y, al mismo tiempo, la precisión es de un asombroso 98,3%. Ahora, echemos un vistazo a la matriz de confusión de nuevo para los resultados de este modelo:

Mirando los casos mal clasificados, podemos observar que 8 casos malignos han sido clasificados incorrectamente como benignos (falsos negativos). Además, sólo un caso benigno ha sido clasificado como maligno (Falso positivo).
Un falso negativo es más grave ya que se ha ignorado una enfermedad, lo que puede llevar a la muerte del paciente. Al mismo tiempo, un falso positivo llevaría a un tratamiento innecesario, lo que supondría un coste adicional.
Intentemos minimizar los falsos negativos utilizando la búsqueda en cuadrícula para encontrar los parámetros óptimos. La búsqueda en cuadrícula puede utilizarse para mejorar cualquier métrica de evaluación específica.
La métrica en la que debemos centrarnos para reducir los falsos negativos es Recall.
Búsqueda en cuadrícula para maximizar Recall
Output :


Los hiperparámetros que sintonizamos son:
- Penalización: l1 o l2 que especie la norma utilizada en la penalización.
- C: Inverso de la fuerza de regularización- valores más pequeños de C especifican una regularización más fuerte.
Además, en la función Grid-search, tenemos el parámetro scoring donde podemos especificar la métrica para evaluar el modelo en (Hemos elegido recall como la métrica). En la matriz de confusión que aparece a continuación, podemos ver que el número de falsos negativos se ha reducido, pero a costa de un aumento de los falsos positivos. La recuperación después de la búsqueda en la cuadrícula ha pasado del 88,2% al 91,1%, mientras que la precisión ha bajado del 98,3% al 87,3%.

Puede ajustar aún más el modelo para lograr un equilibrio entre la precisión y la recuperación utilizando la puntuación ‘f1’ como métrica de evaluación. Consulta este artículo para entender mejor las métricas de evaluación.
La búsqueda en cuadrícula construye un modelo para cada combinación de hiperparámetros especificada y evalúa cada modelo. Una técnica más eficiente para el ajuste de hiperparámetros es la búsqueda aleatoria – donde se utilizan combinaciones aleatorias de los hiperparámetros para encontrar la mejor solución.
Leave a Reply