Datenmaskierung
Was ist Datenmaskierung?
Datenmaskierung ist eine Möglichkeit, eine gefälschte, aber realistische Version Ihrer Unternehmensdaten zu erstellen. Ziel ist es, vertrauliche Daten zu schützen und gleichzeitig eine funktionale Alternative bereitzustellen, wenn echte Daten nicht benötigt werden, z. B. bei Benutzerschulungen, Verkaufsdemonstrationen oder Softwaretests.
Datenmaskierungsprozesse ändern die Werte der Daten, während sie das gleiche Format verwenden. Ziel ist es, eine Version zu erstellen, die nicht entschlüsselt oder zurückentwickelt werden kann. Es gibt mehrere Möglichkeiten, die Daten zu verändern, einschließlich Zeichenmischung, Wort- oder Zeichenersetzung und Verschlüsselung.
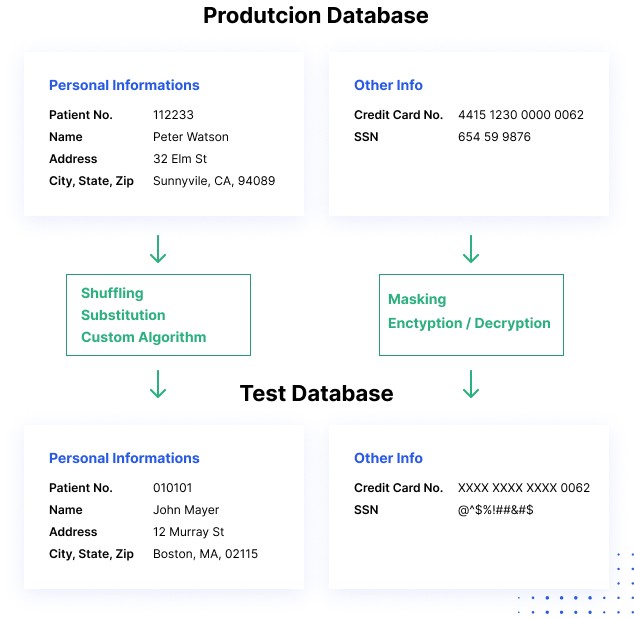
Wie funktioniert Datenmaskierung
Warum ist Datenmaskierung wichtig?
Es gibt mehrere Gründe, warum Datenmaskierung für viele Unternehmen unerlässlich ist:
- Datenmaskierung löst mehrere kritische Bedrohungen – Datenverlust, Datenexfiltration, Insider-Bedrohungen oder Account-Kompromittierung und unsichere Schnittstellen mit Systemen von Drittanbietern.
- Reduziert Datenrisiken im Zusammenhang mit der Cloud-Einführung.
- Macht Daten für Angreifer unbrauchbar, während viele ihrer inhärenten funktionalen Eigenschaften beibehalten werden.
- Ermöglicht die gemeinsame Nutzung von Daten mit autorisierten Benutzern, wie Testern und Entwicklern, ohne die Produktionsdaten offenzulegen.
- Kann zur Datenbereinigung verwendet werden – normales Löschen von Dateien hinterlässt immer noch Datenspuren auf Speichermedien, während die Bereinigung die alten Werte durch maskierte Werte ersetzt.
Datenmaskierungstypen
Es gibt mehrere Arten von Datenmaskierungstypen, die üblicherweise zum Schutz sensibler Daten verwendet werden.
Statische Datenmaskierung
Statische Datenmaskierungsprozesse können Ihnen helfen, eine bereinigte Kopie der Datenbank zu erstellen. Der Prozess ändert alle sensiblen Daten, bis eine Kopie der Datenbank sicher freigegeben werden kann. In der Regel wird dabei eine Sicherungskopie einer Produktionsdatenbank erstellt, die in eine separate Umgebung geladen wird, aus der alle unnötigen Daten entfernt werden, und dann werden die Daten maskiert, während sie sich im Ruhezustand befinden. Die maskierte Kopie kann dann an den Zielort verschoben werden.
Deterministische Datenmaskierung
Bei der Datenmaskierung werden zwei Datensätze, die denselben Datentyp haben, so zugeordnet, dass ein Wert immer durch einen anderen Wert ersetzt wird. Zum Beispiel wird der Name „John Smith“ immer durch „Jim Jameson“ ersetzt, wo immer er in einer Datenbank erscheint. Diese Methode ist für viele Szenarien praktisch, aber von Natur aus weniger sicher.
On-the-Fly Data Masking
Die Maskierung von Daten, während sie von Produktionssystemen auf Test- oder Entwicklungssysteme übertragen werden, bevor die Daten auf der Festplatte gespeichert werden. Unternehmen, die häufig Software bereitstellen, können keine Sicherungskopie der Quelldatenbank erstellen und die Maskierung anwenden, sondern benötigen eine Möglichkeit, Daten kontinuierlich aus der Produktion in mehrere Testumgebungen zu übertragen.
Bei der fliegenden Maskierung werden kleinere Teilmengen der maskierten Daten gesendet, wenn sie benötigt werden. Jede Teilmenge der maskierten Daten wird in der Entwicklungs-/Testumgebung zur Verwendung durch das Nicht-Produktionssystem gespeichert.
Es ist wichtig, die fliegende Maskierung gleich zu Beginn eines Entwicklungsprojekts auf jeden Feed von einem Produktionssystem zu einer Entwicklungsumgebung anzuwenden, um Konformitäts- und Sicherheitsprobleme zu vermeiden.
Dynamische Datenmaskierung
Ähnlich wie bei der fliegenden Maskierung, aber die Daten werden nie in einem sekundären Datenspeicher in der Entwicklungs-/Testumgebung gespeichert. Vielmehr werden sie direkt vom Produktionssystem gestreamt und von einem anderen System in der Entwicklungs-/Testumgebung genutzt.
Techniken zur Datenmaskierung
Wir wollen uns nun einige gängige Methoden ansehen, mit denen Unternehmen sensible Daten maskieren. Beim Schutz von Daten können IT-Fachleute eine Reihe von Techniken anwenden.
Datenverschlüsselung
Wenn Daten verschlüsselt werden, sind sie unbrauchbar, es sei denn, der Betrachter hat den Entschlüsselungsschlüssel. Im Wesentlichen werden die Daten durch den Verschlüsselungsalgorithmus maskiert. Dies ist die sicherste Form der Datenmaskierung, aber sie ist auch kompliziert zu implementieren, da sie eine Technologie zur fortlaufenden Datenverschlüsselung und Mechanismen zur Verwaltung und gemeinsamen Nutzung von Verschlüsselungsschlüsseln erfordert
Data Scrambling
Zeichen werden in zufälliger Reihenfolge neu angeordnet und ersetzen den ursprünglichen Inhalt. Zum Beispiel könnte eine ID-Nummer wie 76498 in einer Produktionsdatenbank durch 84967 in einer Testdatenbank ersetzt werden. Diese Methode ist sehr einfach zu implementieren, kann aber nur auf einige Datentypen angewandt werden und ist weniger sicher.
Nulling Out
Daten scheinen zu fehlen oder „null“ zu sein, wenn sie von einem unbefugten Benutzer angesehen werden. Dadurch werden die Daten für Entwicklungs- und Testzwecke weniger nützlich.
Wertabweichung
Originaldatenwerte werden durch eine Funktion ersetzt, z. B. die Differenz zwischen dem niedrigsten und dem höchsten Wert in einer Reihe. Wenn ein Kunde beispielsweise mehrere Produkte gekauft hat, kann der Kaufpreis durch einen Bereich zwischen dem höchsten und dem niedrigsten gezahlten Preis ersetzt werden. Dies kann nützliche Daten für viele Zwecke liefern, ohne dass der ursprüngliche Datensatz offengelegt wird.
Datensubstitution
Datenwerte werden durch gefälschte, aber realistische Alternativwerte ersetzt. Zum Beispiel werden echte Kundennamen durch eine zufällige Auswahl von Namen aus einem Telefonbuch ersetzt.
Datenmischung
Ähnlich wie bei der Substitution, nur dass die Datenwerte innerhalb desselben Datensatzes ausgetauscht werden. Die Daten werden in jeder Spalte mit einer zufälligen Reihenfolge neu angeordnet, z. B. durch Umschalten zwischen echten Kundennamen in mehreren Kundendatensätzen. Der Ausgabesatz sieht aus wie echte Daten, zeigt aber nicht die echten Informationen für jede Person oder jeden Datensatz.
Pseudonymisierung
Nach der EU-Datenschutzgrundverordnung (GDPR) wurde ein neuer Begriff eingeführt, um Verfahren wie Datenmaskierung, Verschlüsselung und Hashing zum Schutz personenbezogener Daten abzudecken: Pseudonymisierung.
Pseudonymisierung, wie in der GDPR definiert, ist jede Methode, die sicherstellt, dass Daten nicht zur persönlichen Identifizierung verwendet werden können. Sie erfordert die Entfernung direkter Identifikatoren und vorzugsweise die Vermeidung mehrerer Identifikatoren, die in Kombination eine Person identifizieren können.
Außerdem sollten Verschlüsselungsschlüssel oder andere Daten, die verwendet werden können, um zu den ursprünglichen Datenwerten zurückzukehren, separat und sicher gespeichert werden.
Best Practices für die Datenmaskierung
Bestimmen des Projektumfangs
Um die Datenmaskierung effektiv durchführen zu können, sollten Unternehmen wissen, welche Informationen geschützt werden müssen, wer berechtigt ist, sie einzusehen, welche Anwendungen die Daten verwenden und wo sie sich befinden, sowohl in den Produktions- als auch in den Nicht-Produktionsbereichen. Auf dem Papier mag dies einfach erscheinen, doch aufgrund der Komplexität der Abläufe und mehrerer Geschäftsbereiche kann dieser Prozess einen erheblichen Aufwand erfordern und muss als separate Projektphase geplant werden.
Referentielle Integrität sicherstellen
Referentielle Integrität bedeutet, dass jeder „Typ“ von Informationen, die von einer Geschäftsanwendung kommen, mit demselben Algorithmus maskiert werden muss.
In großen Organisationen ist ein einziges Datenmaskierungstool, das im gesamten Unternehmen eingesetzt wird, nicht praktikabel. Jeder Geschäftszweig muss möglicherweise aufgrund von Budget-/Geschäftsanforderungen, unterschiedlichen IT-Verwaltungspraktiken oder unterschiedlichen Sicherheits-/Vorschriftenanforderungen seine eigene Datenmaskierung implementieren.
Stellen Sie sicher, dass die verschiedenen Datenmaskierungstools und -praktiken im gesamten Unternehmen synchronisiert werden, wenn es um dieselbe Art von Daten geht. So lassen sich spätere Probleme vermeiden, wenn Daten geschäftsbereichsübergreifend verwendet werden müssen.
Sichern Sie die Datenmaskierungsalgorithmen
Es ist von entscheidender Bedeutung zu überlegen, wie die Algorithmen zur Datenerstellung sowie alternative Datensätze oder Wörterbücher, die zur Verschlüsselung der Daten verwendet werden, geschützt werden können. Da nur autorisierte Benutzer Zugang zu den echten Daten haben sollten, sind diese Algorithmen als äußerst sensibel zu betrachten. Wenn jemand erfährt, welche wiederholbaren Maskierungsalgorithmen verwendet werden, kann er große Blöcke sensibler Informationen zurückentwickeln.
Eine bewährte Praxis der Datenmaskierung, die in einigen Vorschriften ausdrücklich gefordert wird, ist die Gewährleistung der Aufgabentrennung. So legt beispielsweise das IT-Sicherheitspersonal fest, welche Methoden und Algorithmen im Allgemeinen verwendet werden, aber spezifische Algorithmuseinstellungen und Datenlisten sollten nur den Dateneigentümern in der jeweiligen Abteilung zugänglich sein.
Datenmaskierung mit Imperva
Imperva ist eine Sicherheitslösung, die Datenmaskierungs- und Verschlüsselungsfunktionen bietet und es Ihnen ermöglicht, sensible Daten so zu verschleiern, dass sie für einen Angreifer unbrauchbar sind, selbst wenn sie irgendwie extrahiert werden.
Die Datensicherheitslösung von Imperva bietet nicht nur Datenmaskierung, sondern schützt Ihre Daten, wo auch immer sie sich befinden – vor Ort, in der Cloud und in hybriden Umgebungen. Darüber hinaus bietet sie Sicherheits- und IT-Teams einen vollständigen Einblick in die Art und Weise, wie auf die Daten zugegriffen wird, wie sie verwendet werden und wie sie innerhalb des Unternehmens verschoben werden.
Unser umfassender Ansatz beruht auf mehreren Schutzebenen, darunter:
- Datenbank-Firewall – blockiert SQL-Injection und andere Bedrohungen, während sie auf bekannte Schwachstellen untersucht wird.
- Benutzerrechteverwaltung: Überwacht den Datenzugriff und die Aktivitäten privilegierter Benutzer, um übermäßige, unangemessene und ungenutzte Berechtigungen zu identifizieren.
- Data Loss Prevention (DLP): Untersucht Daten in Bewegung, im Ruhezustand auf Servern, in Cloud-Speichern oder auf Endgeräten.
- Analyse des Benutzerverhaltens – erstellt Grundlinien des Datenzugriffsverhaltens und nutzt maschinelles Lernen, um abnormale und potenziell riskante Aktivitäten zu erkennen und zu melden.
- Datenerkennung und -klassifizierung – offenbart den Speicherort, das Volumen und den Kontext von Daten vor Ort und in der Cloud.
- Überwachung von Datenbankaktivitäten – Überwacht relationale Datenbanken, Data Warehouses, Big Data und Mainframes, um Echtzeitwarnungen zu Richtlinienverletzungen zu generieren.
- Priorisierung von Warnmeldungen – Imperva nutzt KI und maschinelle Lerntechnologien, um den Strom von Sicherheitsereignissen zu durchleuchten und die wichtigsten zu priorisieren.
Leave a Reply