Datamaskering
Hvad er datamaskering?
Datamaskering er en måde at skabe en falsk, men realistisk version af dine organisatoriske data på. Målet er at beskytte følsomme data og samtidig give et funktionelt alternativ, når der ikke er brug for rigtige data – f.eks. i forbindelse med brugeruddannelse, salgsdemoer eller softwaretestning.
Datamaskeringsprocesser ændrer værdierne i dataene, mens de bruger det samme format. Målet er at skabe en version, der ikke kan dechifreres eller omvendt manipuleres. Der er flere måder at ændre dataene på, bl.a. ved at blande tegn, udskiftning af ord eller tegn og kryptering.
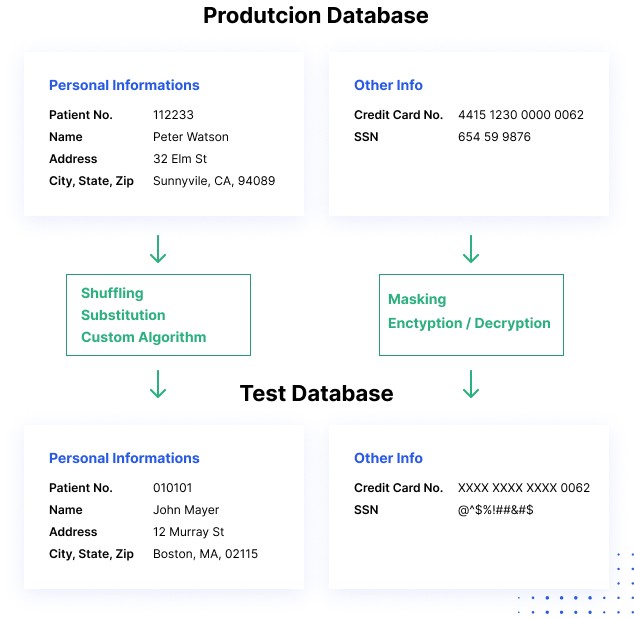
Hvordan datamaskering fungerer
Hvorfor er datamaskering vigtig?
Der er flere grunde til, at datamaskering er vigtig for mange organisationer:
- Datamaskering løser flere kritiske trusler – datatab, dataekfiltrering, insidertrusler eller kompromittering af konti og usikre grænseflader med tredjepartssystemer.
- Reducerer datarisici i forbindelse med cloud-adoption.
- Gør data ubrugelige for en angriber, samtidig med at mange af deres iboende funktionelle egenskaber bevares.
- Gør det muligt at dele data med autoriserede brugere, f.eks. testere og udviklere, uden at udsætte produktionsdata.
- Kan bruges til datasanering – normal sletning af filer efterlader stadig spor af data på lagermedier, mens sanering erstatter de gamle værdier med maskerede værdier.
Datamaskeringstyper
Der findes flere typer datamaskeringstyper, der almindeligvis bruges til at sikre følsomme data.
Statisk datamaskering
Statiske datamaskeringsprocesser kan hjælpe dig med at oprette en renset kopi af databasen. Processen ændrer alle følsomme data, indtil en kopi af databasen kan deles på sikker vis. Typisk indebærer processen, at der oprettes en sikkerhedskopi af en database i produktion, at den indlæses i et separat miljø, at alle unødvendige data fjernes, og at dataene derefter maskeres, mens de er i stase. Den maskerede kopi kan derefter skubbes til målplaceringen.
Deterministisk datamaskering
Involverer kortlægning af to datasæt, der har samme datatype, på en sådan måde, at den ene værdi altid erstattes af en anden værdi. F.eks. erstattes navnet “John Smith” altid med “Jim Jameson”, overalt hvor det forekommer i en database. Denne metode er praktisk i mange scenarier, men er i sagens natur mindre sikker.
On-the-Fly Data Masking
Maskering af data, mens de overføres fra produktionssystemer til test- eller udviklingssystemer, før dataene gemmes på disk. Organisationer, der udruller software ofte, kan ikke oprette en sikkerhedskopi af kildedatabasen og anvende maskering – de har brug for en måde til løbende at strømme data fra produktion til flere testmiljøer.
Maskering undervejs sender mindre delmængder af maskerede data, når det er påkrævet. Hver delmængde af maskerede data gemmes i dev/testmiljøet til brug for det ikke-produktionsbaserede system.
Det er vigtigt at anvende on-the-fly maskering på ethvert feed fra et produktionssystem til et udviklingsmiljø helt fra starten af et udviklingsprojekt for at forhindre overensstemmelses- og sikkerhedsproblemer.
Dynamisk datamaskering
Lignende til on-the-fly maskering, men data gemmes aldrig i et sekundært datalager i dev/testmiljøet. I stedet streames de direkte fra produktionssystemet og forbruges af et andet system i dev/test-miljøet.
Datamaskeringsteknikker
Lad os gennemgå et par almindelige måder, hvorpå organisationer anvender maskering på følsomme data. Når de it-professionelle beskytter data, kan de bruge en række forskellige teknikker.
Datakryptering
Når data krypteres, bliver de ubrugelige, medmindre seeren har dekrypteringsnøglen. I det væsentlige er data maskeret af krypteringsalgoritmen. Dette er den mest sikre form for datamaskering, men den er også kompleks at implementere, fordi den kræver en teknologi til at udføre løbende datakryptering og mekanismer til at administrere og dele krypteringsnøgler
Data Scrambling
Tegn omorganiseres i tilfældig rækkefølge og erstatter det oprindelige indhold. F.eks. kan et ID-nummer som 76498 i en produktionsdatabase blive erstattet af 84967 i en testdatabase. Denne metode er meget enkel at implementere, men kan kun anvendes på visse typer data, og den er mindre sikker.
Nulling Out
Data fremstår som manglende eller “nul”, når de ses af en uautoriseret bruger. Dette gør dataene mindre anvendelige til udviklings- og testformål.
Værdivarians
Originale dataværdier erstattes af en funktion, f.eks. forskellen mellem den laveste og højeste værdi i en serie. Hvis en kunde f.eks. har købt flere produkter, kan købsprisen erstattes med en række mellem den højeste og laveste betalte pris. Dette kan give nyttige data til mange formål uden at afsløre det oprindelige datasæt.
Datasubstitution
Dataværdier erstattes med falske, men realistiske, alternative værdier. Eksempelvis erstattes rigtige kundenavne med et tilfældigt udvalg af navne fra en telefonbog.
Data Shuffling
Lignende substitution, bortset fra at dataværdierne byttes om inden for det samme datasæt. Data omarrangeres i hver kolonne ved hjælp af en tilfældig sekvens; f.eks. skift mellem rigtige kundenavne på tværs af flere kundeposter. Output-sættet ligner rigtige data, men viser ikke de rigtige oplysninger for hver enkelt person eller datapost.
Pseudonymisering
I henhold til EU’s generelle forordning om databeskyttelse (GDPR) er der blevet indført et nyt begreb til at dække processer som datamaskering, kryptering og hashing for at beskytte personoplysninger: pseudonymisering.
Pseudonymisering, som defineret i GDPR, er enhver metode, der sikrer, at data ikke kan bruges til personlig identifikation. Det kræver, at direkte identifikatorer fjernes, og at man helst undgår flere identifikatorer, der, når de kombineres, kan identificere en person.
Dertil kommer, at krypteringsnøgler eller andre data, der kan bruges til at vende tilbage til de oprindelige dataværdier, bør opbevares separat og sikkert.
Bedste praksis for datamaskering
Bestem projektets omfang
For effektivt at kunne udføre datamaskering bør virksomheder vide, hvilke oplysninger der skal beskyttes, hvem der er autoriseret til at se dem, hvilke applikationer der bruger dataene, og hvor de befinder sig, både i produktions- og ikke-produktionsdomæner. Selv om dette kan virke let på papiret, kan denne proces på grund af kompleksiteten af driften og flere forretningsområder kræve en betydelig indsats og skal planlægges som en separat fase af projektet.
Sikre referentiel integritet
Referentiel integritet betyder, at hver “type” information, der kommer fra en forretningsapplikation, skal maskeres ved hjælp af den samme algoritme.
I store organisationer er det ikke muligt at bruge et enkelt datamaskeringsværktøj, der anvendes i hele virksomheden. Det kan være nødvendigt, at hver enkelt forretningslinje skal implementere sin egen datamaskering på grund af budget-/forretningskrav, forskellige it-administrationspraksis eller forskellige sikkerheds-/lovgivningskrav.
Sørg for, at forskellige datamaskeringsværktøjer og -praksis på tværs af organisationen er synkroniseret, når der er tale om den samme type data. Dette vil forhindre udfordringer senere, når data skal bruges på tværs af forretningsområder.
Sikre datamaskeringsalgoritmerne
Det er afgørende at overveje, hvordan man beskytter de algoritmer, der laver data, samt alternative datasæt eller ordbøger, der bruges til at forvrænge dataene. Da kun autoriserede brugere bør have adgang til de rigtige data, bør disse algoritmer betragtes som yderst følsomme. Hvis nogen får kendskab til, hvilke gentagelige maskeringsalgoritmer der anvendes, kan de foretage reverse engineering af store blokke af følsomme oplysninger.
En bedste praksis for datamaskering, som udtrykkeligt kræves i nogle bestemmelser, er at sikre adskillelse af opgaver. F.eks. bestemmer it-sikkerhedspersonalet, hvilke metoder og algoritmer der generelt skal anvendes, men specifikke algoritmeindstillinger og datalister bør kun være tilgængelige for dataejerne i den relevante afdeling.
Datamaskering med Imperva
Imperva er en sikkerhedsløsning, der giver mulighed for datamaskering og kryptering, så du kan sløre følsomme data, så de er ubrugelige for en angriber, selv hvis de på en eller anden måde bliver udtrukket.
Ud over at give datamaskering beskytter Impervas datasikkerhedsløsning dine data, uanset hvor de befinder sig – i lokaler, i skyen og i hybride miljøer. Den giver også sikkerheds- og it-teams fuld indsigt i, hvordan dataene bliver tilgået, brugt og flyttet rundt i organisationen.
Vores omfattende tilgang er baseret på flere beskyttelseslag, herunder:
- Database firewall – blokerer SQL-injektion og andre trusler, samtidig med at den evaluerer for kendte sårbarheder.
- Styring af brugerrettigheder – overvåger dataadgang og aktiviteter for privilegerede brugere for at identificere overdrevne, uhensigtsmæssige og ubrugte privilegier.
- Forebyggelse af datatab (DLP) – inspicerer data i bevægelse, i hvile på servere, i cloudlagring eller på slutpunktsenheder.
- Analyse af brugeradfærd – etablerer basislinjer for dataadgangsadfærd, bruger maskinlæring til at opdage og advare om unormal og potentielt risikabel aktivitet.
- Dataopdagelse og -klassificering – afslører placeringen, mængden og konteksten af data i lokalerne og i skyen.
- Overvågning af databaseaktivitet – overvåger relationelle databaser, datawarehouses, big data og mainframes for at generere advarsler i realtid om overtrædelser af politikker.
- Prioritering af advarsler – Imperva bruger AI og maskinlæringsteknologi til at se på tværs af strømmen af sikkerhedshændelser og prioritere dem, der har størst betydning.
Leave a Reply