Maskování dat
Co je maskování dat?
Maskování dat je způsob, jak vytvořit falešnou, ale reálnou verzi dat vaší organizace. Cílem je chránit citlivá data a zároveň poskytnout funkční alternativu v případech, kdy skutečná data nejsou potřeba – například při školení uživatelů, prodejních ukázkách nebo testování softwaru.
Procesy maskování dat mění hodnoty dat při použití stejného formátu. Cílem je vytvořit verzi, kterou nelze dešifrovat nebo zpětně analyzovat. Existuje několik způsobů, jak data změnit, včetně přehazování znaků, záměny slov nebo znaků a šifrování.
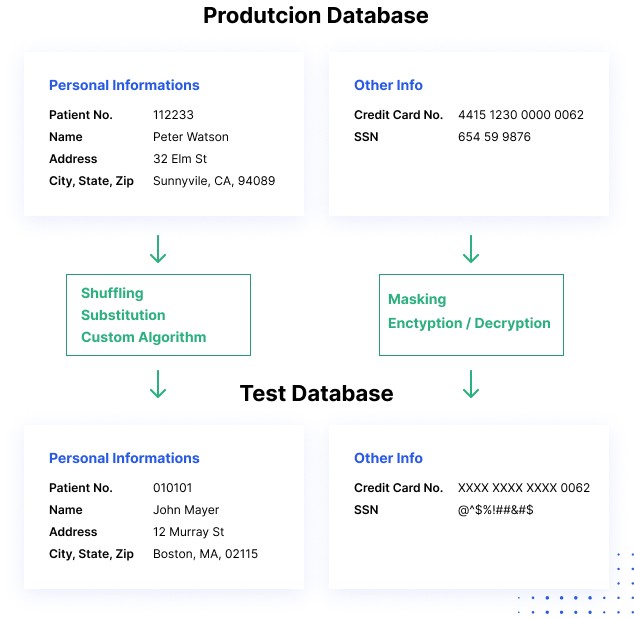
Jak funguje maskování dat
Proč je maskování dat důležité?
Zde je několik důvodů, proč je maskování dat pro mnoho organizací nezbytné:
- Maskování dat řeší několik kritických hrozeb – ztrátu dat, exfiltraci dat, vnitřní hrozby nebo kompromitaci účtů a nezabezpečená rozhraní se systémy třetích stran.
- Snižuje rizika pro data spojená s přijetím cloudu.
- Způsobuje, že data jsou pro útočníka nepoužitelná, a přitom zachovává mnoho jejich přirozených funkčních vlastností.
- Umožňuje sdílení dat s oprávněnými uživateli, jako jsou testeři a vývojáři, aniž by došlo k odhalení produkčních dat.
- Může být použit pro sanitaci dat – běžné mazání souborů stále zanechává stopy dat na paměťových médiích, zatímco sanitace nahrazuje staré hodnoty maskovanými.
Typy maskování dat
K zabezpečení citlivých dat se běžně používá několik typů maskování dat.
Statické maskování dat
Procesy statického maskování dat mohou pomoci vytvořit sanitizovanou kopii databáze. Proces mění všechna citlivá data, dokud není možné bezpečně sdílet kopii databáze. Obvykle proces zahrnuje vytvoření záložní kopie produkční databáze, její načtení do odděleného prostředí, odstranění všech nepotřebných dat a následné maskování dat, dokud jsou v klidu. Maskovanou kopii pak lze přesunout do cílového umístění.
Deterministické maskování dat
Obsahuje mapování dvou sad dat, které mají stejný typ dat, takovým způsobem, že jedna hodnota je vždy nahrazena jinou hodnotou. Například jméno „John Smith“ je vždy nahrazeno jménem „Jim Jameson“, a to všude, kde se v databázi vyskytuje. Tato metoda je vhodná pro mnoho scénářů, ale je ve své podstatě méně bezpečná.
Maskování dat za chodu
Maskování dat při jejich přenosu z produkčních systémů do testovacích nebo vývojových systémů před uložením dat na disk. Organizace, které často nasazují software, nemohou vytvořit záložní kopii zdrojové databáze a použít maskování – potřebují způsob, jak nepřetržitě přenášet data z produkčních systémů do více testovacích prostředí.
Maskování za běhu odesílá menší podmnožiny maskovaných dat, když je to potřeba. Každá podmnožina maskovaných dat je uložena v dev/testovacím prostředí pro použití v neprodukčním systému.
Je důležité aplikovat maskování za chodu na jakýkoli tok dat z produkčního systému do vývojového prostředí, a to hned na začátku vývojového projektu, aby se předešlo problémům s dodržováním předpisů a zabezpečením.
Dynamické maskování dat
Podobné maskování za chodu, ale data se nikdy neukládají do sekundárního úložiště dat v dev/testovacím prostředí. Spíše jsou streamována přímo z produkčního systému a spotřebovávána jiným systémem v dev/testovacím prostředí.
Techniky maskování dat
Podívejme se na několik běžných způsobů, jak organizace používají maskování citlivých dat. Při ochraně dat mohou IT profesionálové používat různé techniky.
Šifrování dat
Pokud jsou data zašifrována, stávají se nepoužitelnými, pokud prohlížející nemá dešifrovací klíč. Data jsou v podstatě maskována šifrovacím algoritmem. Jedná se o nejbezpečnější formu maskování dat, ale je také složitá na implementaci, protože vyžaduje technologii pro průběžné šifrování dat a mechanismy pro správu a sdílení šifrovacích klíčů
Data Scrambling
Znaky jsou přeuspořádány v náhodném pořadí a nahrazují původní obsah. Například identifikační číslo, jako je 76498 v produkční databázi, může být v testovací databázi nahrazeno číslem 84967. Tato metoda je velmi jednoduchá na implementaci, ale lze ji použít pouze pro některé typy dat a je méně bezpečná.
Nulování
Data se při zobrazení neoprávněným uživatelem jeví jako chybějící nebo „nulová“. Tím se data stávají méně užitečnými pro účely vývoje a testování.
Variance hodnot
Původní hodnoty dat jsou nahrazeny funkcí, například rozdílem mezi nejnižší a nejvyšší hodnotou v řadě. Například pokud zákazník zakoupil několik produktů, lze nákupní cenu nahradit rozmezím mezi nejvyšší a nejnižší zaplacenou cenou. Tím lze získat užitečné údaje pro mnoho účelů, aniž by došlo k prozrazení původního souboru dat.
Zastoupení dat
Datové hodnoty jsou nahrazeny falešnými, ale reálnými alternativními hodnotami. Například skutečná jména zákazníků jsou nahrazena náhodným výběrem jmen z telefonního seznamu.
Přehazování dat
Podobné nahrazování, s tím rozdílem, že hodnoty dat jsou přehazovány v rámci stejného souboru dat. Data jsou v každém sloupci přeskupena pomocí náhodné posloupnosti; například přepínání mezi skutečnými jmény zákazníků v rámci více záznamů o zákaznících. Výstupní soubor vypadá jako skutečná data, ale nezobrazuje skutečné informace o každé osobě nebo datovém záznamu.
Pseudonymizace
Podle obecného nařízení EU o ochraně osobních údajů (GDPR) byl zaveden nový termín, který zahrnuje procesy jako maskování dat, šifrování a hashování pro ochranu osobních údajů: pseudonymizace.
Pseudonymizace, jak je definována v GDPR, je jakákoli metoda, která zajišťuje, že data nelze použít k osobní identifikaci. Vyžaduje odstranění přímých identifikátorů a pokud možno zamezení vícenásobných identifikátorů, jejichž kombinací lze osobu identifikovat.
Kromě toho by měly být šifrovací klíče nebo jiné údaje, které lze použít k návratu k původním hodnotám údajů, uloženy odděleně a bezpečně.
Nejlepší postupy maskování dat
Určení rozsahu projektu
Pro efektivní provedení maskování dat by společnosti měly vědět, jaké informace je třeba chránit, kdo je oprávněn je vidět, které aplikace data používají a kde se nacházejí, a to jak v produkční, tak v neprodukční doméně. I když se to na papíře může zdát snadné, vzhledem ke složitosti provozu a více liniím podnikání může tento proces vyžadovat značné úsilí a musí být naplánován jako samostatná fáze projektu.
Zajištění referenční integrity
Referenční integrita znamená, že každý „typ“ informací přicházejících z podnikové aplikace musí být maskován pomocí stejného algoritmu.
Ve velkých organizacích není možné použít jediný nástroj pro maskování dat v celém podniku. Každá linie podniku může být nucena zavést vlastní maskování dat z důvodu rozpočtových/obchodních požadavků, různých postupů správy IT nebo různých bezpečnostních/regulačních požadavků.
Zajistěte, aby různé nástroje a postupy maskování dat v rámci organizace byly synchronizovány, pokud pracují se stejným typem dat. Předejdete tak pozdějším problémům, když bude třeba data použít napříč podnikovými liniemi.
Zabezpečení algoritmů maskování dat
Je velmi důležité zvážit, jak ochránit algoritmy pro tvorbu dat, stejně jako alternativní datové sady nebo slovníky používané k maskování dat. Protože ke skutečným datům by měli mít přístup pouze oprávnění uživatelé, měly by být tyto algoritmy považovány za mimořádně citlivé. Pokud se někdo dozví, které opakovatelné maskovací algoritmy se používají, může zpětným inženýrstvím získat velké bloky citlivých informací.
Osvědčeným postupem pro maskování dat, který je výslovně vyžadován některými předpisy, je zajištění oddělení povinností. Například pracovníci zabezpečení IT určují, jaké metody a algoritmy budou obecně použity, ale konkrétní nastavení algoritmů a seznamy dat by měly být přístupné pouze vlastníkům dat v příslušném oddělení.
Maskování dat s řešením Imperva
Imperva je bezpečnostní řešení, které poskytuje funkce maskování a šifrování dat, což umožňuje zakrýt citlivá data tak, aby byla pro útočníka nepoužitelná, i kdyby je nějakým způsobem extrahoval.
Kromě maskování dat chrání řešení zabezpečení dat od společnosti Imperva vaše data bez ohledu na to, kde se nacházejí – v prostorách, v cloudu i v hybridních prostředích. Zároveň poskytuje bezpečnostním a IT týmům plný přehled o tom, jak jsou data zpřístupňována, používána a přesouvána v rámci organizace.
Náš komplexní přístup se opírá o více vrstev ochrany, včetně:
- Databázové brány firewall – blokuje SQL injection a další hrozby a zároveň vyhodnocuje známé zranitelnosti.
- Správa uživatelských práv – monitoruje přístup k datům a činnosti privilegovaných uživatelů s cílem identifikovat nadměrná, nevhodná a nepoužívaná oprávnění.
- Prevence ztráty dat (DLP) – kontroluje data v pohybu, v klidu na serverech, v cloudových úložištích nebo na koncových zařízeních.
- Analýza chování uživatelů – vytváří základní linie chování při přístupu k datům, využívá strojové učení k detekci a upozornění na abnormální a potenciálně rizikové aktivity.
- Zjišťování a klasifikace dat – odhaluje umístění, objem a kontext dat v lokálním prostředí a v cloudu.
- Monitorování aktivity databází – monitoruje relační databáze, datové sklady, velká data a mainframy a generuje upozornění na porušení zásad v reálném čase.
- Prioritizace upozornění – Imperva využívá technologii umělé inteligence a strojového učení k tomu, aby se podívala na celý proud bezpečnostních událostí a upřednostnila ty, které jsou nejdůležitější.
Leave a Reply