Mřížkové vyhledávání pro ladění modelu
Hiperparametr modelu je vlastnost modelu, která je mimo model a jejíž hodnotu nelze odhadnout z dat. Hodnota hyperparametru musí být nastavena před zahájením procesu učení. Například c u Support Vector Machines, k u k-Nearest Neighbors, počet skrytých vrstev u neuronových sítí.
Naproti tomu parametr je vnitřní vlastnost modelu a jeho hodnotu lze odhadnout z dat. Příkladem jsou beta koeficienty lineární/logistické regrese nebo podpůrné vektory v Support Vector Machines.
Síťové vyhledávání se používá k nalezení optimálních hyperparametrů modelu, které vedou k nejpřesnějším „předpovědím“.
Podívejme se na síťové vyhledávání sestavením klasifikačního modelu na souboru dat o rakovině prsu.
Importujte datovou sadu a zobrazte 10 nejlepších řádků.
Výstup :

Každý řádek v datasetu má jednu ze dvou možných tříd: benigní (reprezentovaná 2) a maligní (reprezentovaná 4). V této datové sadě je také 10 atributů (zobrazených výše), které budou použity pro predikci, kromě čísla kódu vzorku, což je identifikační číslo.
Pro sestavení modelu vyčistěte data a přejmenujte hodnoty tříd na 0/1 (kde 1 představuje maligní případ). Dále sledujme rozložení tříd.
Výstup :

Je 444 benigních a 239 maligních případů.
Výstup :
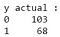
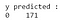
Z výstupu vyplývá, že v testovacím souboru dat je 68 maligních a 103 benigních případů. Náš klasifikátor však předpovídá všechny případy jako benigní (protože se jedná o většinovou třídu).
Vypočítejte metriky hodnocení tohoto modelu.
Výstup :

Přesnost modelu je 60 %.2 %, ale to je případ, kdy přesnost nemusí být nejlepší metrikou pro hodnocení modelu. Podívejme se tedy na další metriky hodnocení:

Na výše uvedeném obrázku je matice záměny s přidanými značkami a barvami pro lepší intuici (kód pro její vygenerování naleznete zde). Pro shrnutí matice záměny : PRAVDIVĚ POZITIVNÍ (TP)= 0,PRAVDIVĚ NEGATIVNÍ (TN)= 103,FALEŠNĚ POZITIVNÍ (FP)= 0, FALEŠNĚ NEGATIVNÍ (FN)= 68. Vzorce pro vyhodnocovací metriky jsou následující :

Protože model neklasifikuje správně žádný zhoubný případ, jsou metriky recall a precision rovny nule.
Teď, když máme základní přesnost, sestavíme logistický regresní model s výchozími parametry a model vyhodnotíme.
Výstup :

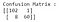
Při sestavení modelu logistické regrese s výchozími parametry máme mnohem „lepší“ model. Přesnost je 94,7 % a zároveň přesnost je ohromujících 98,3 %. Nyní se znovu podívejme na matici záměny výsledků tohoto modelu :

Podíváme-li se na chybně klasifikované případy, můžeme pozorovat, že 8 maligních případů bylo nesprávně klasifikováno jako benigní (falešně negativní). Také pouze jeden benigní případ byl klasifikován jako maligní (False positive).
Falešně negativní případ je závažnější, protože bylo ignorováno onemocnění, které může vést k úmrtí pacienta. Zároveň by falešně pozitivní výsledek vedl ke zbytečné léčbě – čímž by vznikly další náklady.
Pokusíme se minimalizovat falešně negativní výsledky pomocí Grid Search k nalezení optimálních parametrů. Grid Search lze použít ke zlepšení jakékoli konkrétní metriky hodnocení.
Metrikou, na kterou se musíme zaměřit, abychom snížili počet falešně negativních výsledků, je Recall.
Mřížkové vyhledávání pro maximalizaci Recall
Výstup :


Hiperparametry, které jsme vyladili, jsou:
- Penalizace: l1 nebo l2, což je druh normy použité při penalizaci.
- C: Inverzní hodnota síly regularizace – menší hodnoty C určují silnější regularizaci.
Ve funkci Grid-search máme také parametr scoring, kde můžeme určit metriku, podle které se má model hodnotit (My jsme jako metriku zvolili recall). Z níže uvedené matice záměny vidíme, že se snížil počet falešně negativních výsledků, avšak je to za cenu zvýšení počtu falešně pozitivních výsledků. Odvolání po prohledání mřížky vyskočilo z 88,2 % na 91,1 %, zatímco přesnost klesla z 98,3 % na 87,3 %.

Model můžete dále vyladit tak, aby dosáhl rovnováhy mezi přesností a odvoláním, a to tak, že jako metriku hodnocení použijete skóre „f1“. Pro lepší pochopení vyhodnocovacích metrik se podívejte na tento článek.
Mřížkové vyhledávání sestaví model pro každou zadanou kombinaci hyperparametrů a každý model vyhodnotí. Efektivnější technikou pro ladění hyperparametrů je náhodné vyhledávání – při něm se k nalezení nejlepšího řešení používají náhodné kombinace hyperparametrů.
Leave a Reply